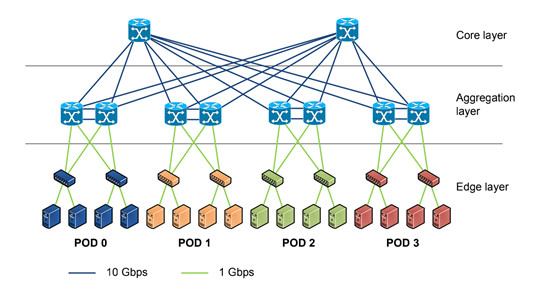
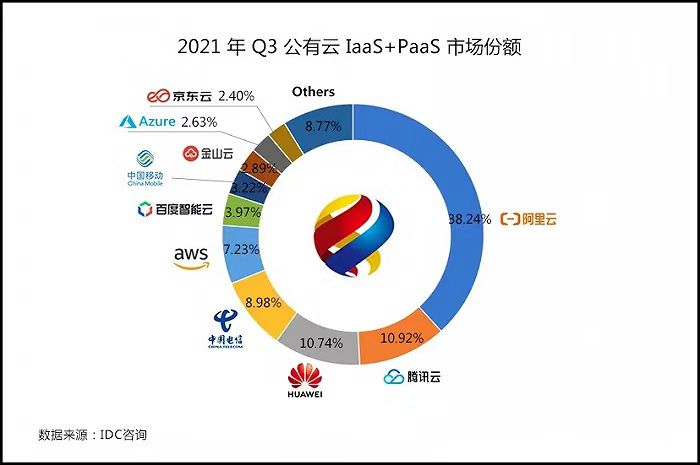
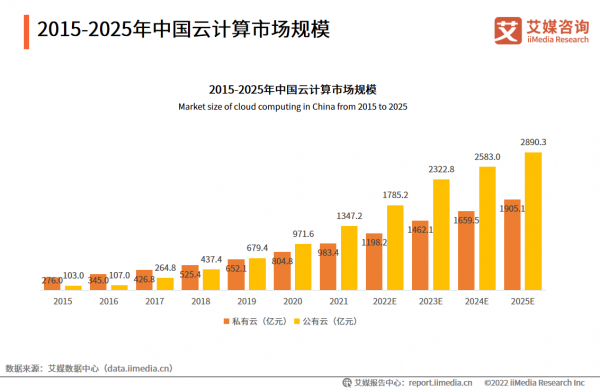
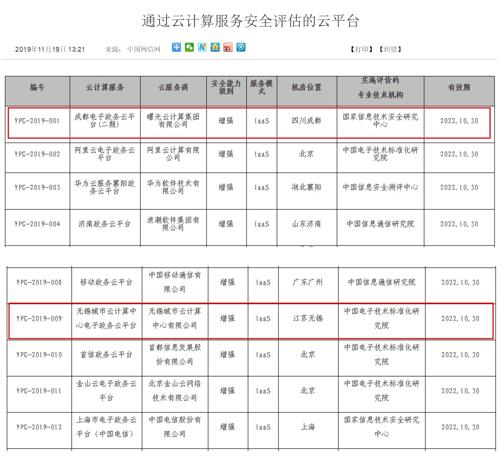
亚马逊云科技宣布AQUAforAmazonRedshift全面可用。作为一种创新的新型分布式硬件加速缓存,AQUA可以使AmazonRedshift查询的运行速度比任何其他云数据仓库最高快10倍。
目前,在美国东部(弗吉尼亚北部)区域、美国西部(俄勒冈)区域、美国东部(俄亥俄)区域、亚太地区(东京)区域和欧洲(爱尔兰)区域运行AmazonRedshiftRA3节点的客户已经可以使用AQUAforAmazonRedshift,其它区域也将很快推出。
据悉,AQUA将计算引入存储层,消除了数据在不同存储位置和计算集群之间不必要的移动,帮助客户避免网络带宽限制。AQUA让客户有了显示更加实时的仪表盘,节省了开发时间,并且让其系统更容易维护。目前RedshiftRA3实例已带有AQUA,客户无需支付额外成本,即可在不修改任何代码的情况下享受AQUA带来的性能提升。
自2012年推出以来,AmazonRedshift已经成为最受欢迎的云数据仓库。此前,亚马逊云科技发布AmazonRedshiftRA3实例,客户可以分别扩展计算和存储,与任何其他云数据仓库相比,提供最高达3倍的性价比。然而,即使数据仓库的性能持续提高,客户需要处理的数据快速增长依然会导致平衡性能和成本效率的两难境地。数据仓库的主流方法是将大量集中存储移至计算节点上进行数据处理。这种方法的挑战在于共享数据和计算节点之间存在大量的数据移动。随着数据量持续快速增长,这种数据移动会使可用的网络带宽饱和,降低性能。除了网络瓶颈之外,CPU无法跟上快速增长的存储性能(SSD存储吞吐量的增长速度比CPU从内存处理数据的能力快6倍),这要么导致新的CPU瓶颈,这迫使更多客户为了更快地完成工作而超额部署计算资源。
AQUAforAmazonRedshift是AmazonRedshift的分布式硬件加速缓存,这是一项针对提高大规模数据分析性能的创新。AQUA将计算引入存储层,因此数据不必在两者之间来回移动。这使得AmazonRedshift的运行速度比任何其他云数据仓库最高快10倍。AQUA缓存可横向扩展,并可跨众多节点并行处理数据。每个节点都包含一个由亚马逊云科技设计的分析处理器组成的硬件模块,可以极大地加速数据压缩、加密和数据处理任务(如扫描、聚合和过滤)。AQUA还为客户提供了额外的好处,即可以在原始存储上进行计算,从而节省了移动数据的时间。有了这个新的架构,以及其带来的数量级的性能提升,Redshift客户可以实现更加实时的仪表盘,节省了开发时间,其系统也更容易维护。