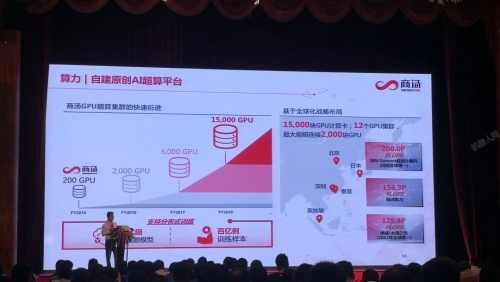
行业领先的人工智能处理器开发商Habana Labs(www.habana.ai) 宣布推出HabanaGaudi™人工智能训练处理器,基于Gaudi的训练系统实现了比拥有相同数量的GPU系统高四倍的处理能力。
Gaudi™处理器的创新架构可实现训练系统性能的近线性扩展,即使是在较小Batch Size的情况下,也能保持高计算力。因此,基于Gaudi™处理器的训练性能可实现从单一设备扩展至由数百个处理器搭建的大型系统的线性扩展。

除了领先的性能,Gaudi™处理器还为人工智能训练带来了另一项“行业第一”。该人工智能处理器片上集成了 RDMA over Converged Ethernet (RoCE v2) 功能,从而让人工智能系统能够使用标准以太网扩展至任何规模。凭借Gaudi™处理器,Habana Labs的客户亦可利用标准以太网交换进行人工智能训练系统的纵向扩展和横向扩展。
同时,以太网交换机已被数据中心应用于计算系统和存储系统的扩展中,在速度和端口数方面可提供几乎无限的可扩展性。另外,与Habana的标准设计相比,基于GPU的系统依赖于专有的系统接口,对系统设计人员来说,这从本质上限制了可扩展性和选择性。
Linley集团首席分析师Linley Gwennap评论说:“Habana Labs推出新产品,其产品组合迅速地从推理处理器扩展到训练处理器,涵盖了神经网络的所有功能。在众多的人工智能训练加速器产品中,Gaudi™处理器能够提供强大的性能,达到行业领先的能效水平。作为首款集成100G以太网链路并支持RoCE的人工智能处理器,Gaudi™为使用行业标准组件构建而成的大型加速器集群提供了强大的支持。”
Gaudi™人工智能训练处理器配备32GB HBM-2内存,目前提供两种规格:
• HL-200 - PCIe卡,设有8个100Gb以太网端口;
• HL-205 - 基于OCP-OAM标准的子卡,设有10个100Gb以太网端口或20个50Gb以太网端口。
另外,Habana推出了一款名为HLS-1的8-Gaudi系统,配备了8个HL-205子卡、PCIe外部主机连接器和24个用于连接现有以太网交换机的100Gbps以太网端口,让客户能够通过在19英寸标准机柜中部署多个HLS-1系统实现性能扩展。
Gaudi™处理器是Habana Labs继去年推出Goya™人工智能推理处理器后的第二款人工智能专用处理器。Goya™处理器自2018年第四季度开始发货,并向业界展示了领先的推理性能,可实现业界最高的吞吐量、功效比(图片/每秒瓦)以及实时。
Habana Labs首席执行官David Dahan 表示:“人工智能模型训练所需的计算能力每年呈指数增长。因此,提高生产率和可扩展性,解决数据中心和云计算对计算能力的迫切需求成为至关重要的任务。凭借Gaudi™处理器的创新架构,Habana Labs带来了业界最高的性能,同时集成了标准以太网,进而实现无限可扩展性。Gaudi™处理器将打破人工智能训练处理器领域的现状。”
Facebook技术和战略总监Vijay Rao表示:“Facebook正在寻找开放的平台以进行行业创新融合。我们很高兴看到Habana Labs的Goya™人工智能推理处理器为Glow机器学习编译器实现后端开源,并且Gaudi™人工智能训练处理器采用OCP加速器模块 (OAM) 规范。”
Gaudi™是一款完全可编程且可定制的处理器,搭载第二代Tensor处理核 (TPC™) 并集成开发工具、库和编译器,共同提供全面而灵活的解决方案。此外,Habana Labs的SynapseAI™软件栈包含一个丰富的内核库和开放工具链,以供客户添加专有内核。
Habana Labs将于2019年下半年面向特定客户提供Gaudi™人工智能训练处理器的样品。